Q:BEV时序融合分为几种,各自优点和区别是什么?
时序融合分为并行融合 Parallel fusion 和递归融合 Recurrent fusion 2种,其中并行融合同时融合处理多个历史帧feat,可获取更丰富完整long-term信息,递归融合当前帧feat只与history feat融合,计算复杂度和内存消耗大幅减少。
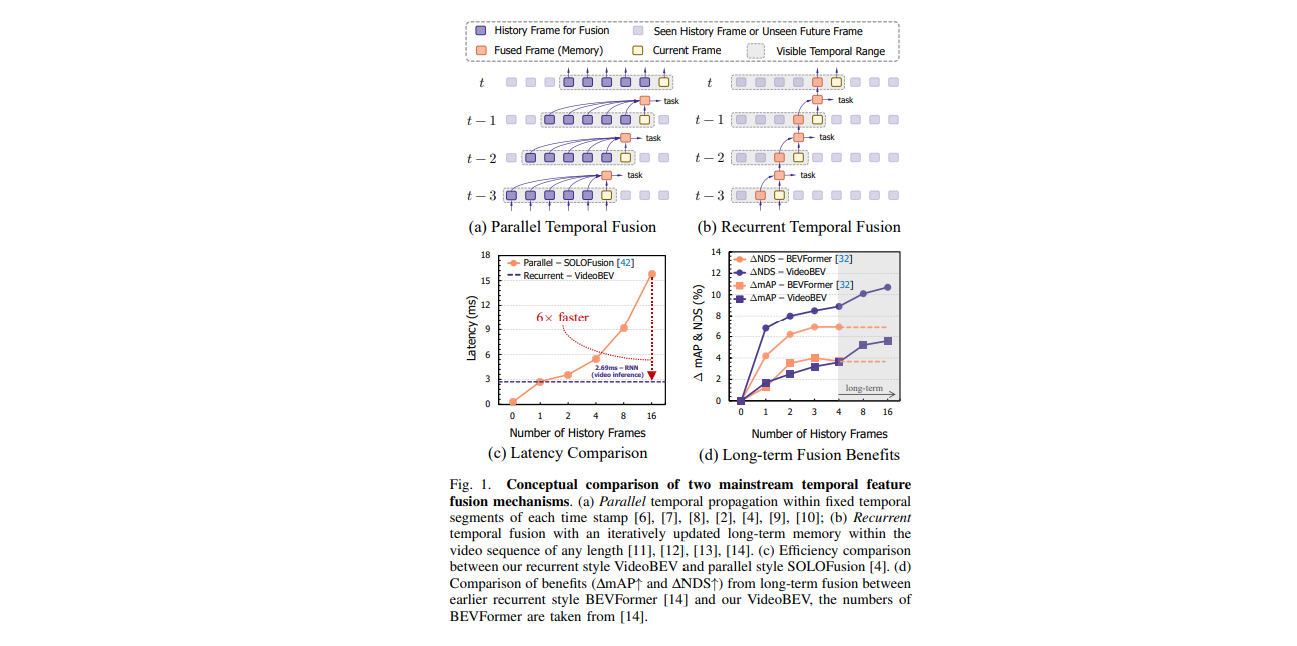
Q:如何在尽量减小计算复杂度的情况下获取long-term BEV时序信息[RecurrentBEV ECCV24]
针对问题:递归融合中历史帧无法梯度回传到融合模块,从而影响融合模块对long-term信息的学习。 解决方案:采用RNN-style梯度回传方式,即对所有相关(最长16个历史帧否则OOM)历史帧的梯度求导作回传。 针对问题:历史帧warp的颗粒度太大,同一对象横跨多个grid经过wrap后存在语义模糊。 解决方案:添加 learnable weight作为加权系数对history feat进行修正即linear加权操作,通过train learnable weight来修正原始粗颗粒度warped history feat。修正后再通过ConvGRU进行recurrent fusion。
Q:学术界如何基于长短时序打出感知组合拳[HENet ECCV24]
采用长短期时序双路并行多任务结构。
Short-term:输入前k个时刻的多视角高清时序帧,采用large backbone提取多尺度2Dfeat,通过BEVStereo中双目深度估计pre depth,基于此用LSS范式计算BEVfeat;
Long-term:输入t-k时刻之前的n个多视角低分辨率时序帧,采用small backbone 提取多尺度2Dfeat,通过BEVDepth中单目深度估计pre depth,并基于LSS求BEVfeat;
将两路BEVfeat按照时间顺序排列,根据多尺度BEVfeat中scale/level不同而分组融合。同一scale的所有时刻BEVfeat,相邻时刻BEVfeat作类似于PAN的操作,此处将PAN中上下采样操作去除,并将add/cat操作改为cat/attention。
融合后得到新的多尺度BEVfeat,然后对此进行通道注意力/SEnet操作,最后取small-sacle BEVfeat(关注全局整体理解)进行Semantic-seg,取large-scale BEVfeat(关注局部信息类似于小目标检测需要用large-sacle feat)进行OD。
Q:如何通过BEV稀疏化减少计算资源[PointBEV CVPR24]
在multi-view camera img上随机/网格式撒点得到采样的sparse 2D point,将2D point拉伸为pillar,并根据不同的z采样得到多个3D point(follow FastBEV),将这些3D point投影到2D feat上提取BEVfeat,其中每个3D point只投影到部分的camera而不是全部的camera,因为只有部分camera能看到该3D point所在的pillar,如果该点投影到多个camera,则对提取到的2D feat作mean然后再作为BEVfeat。
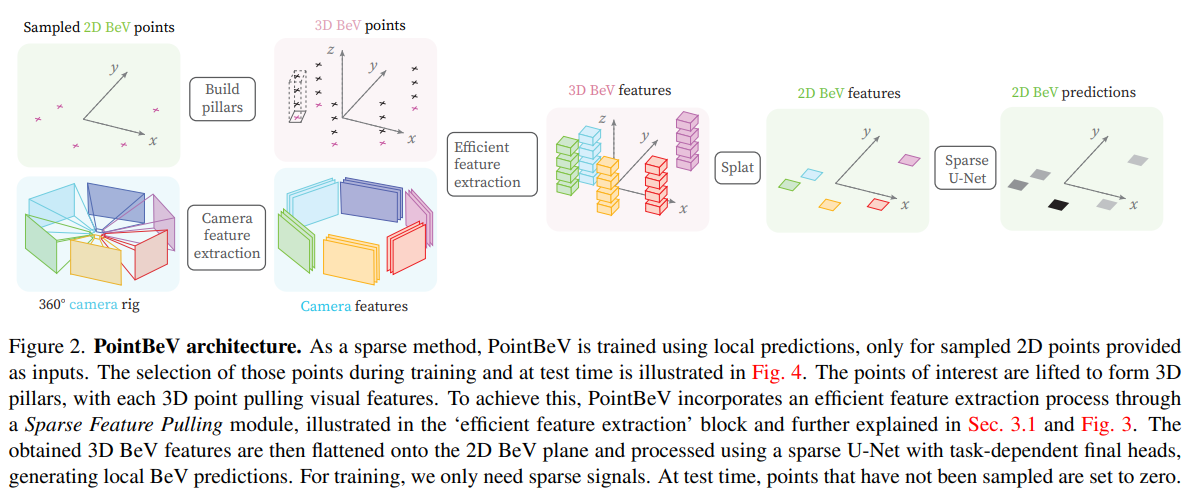
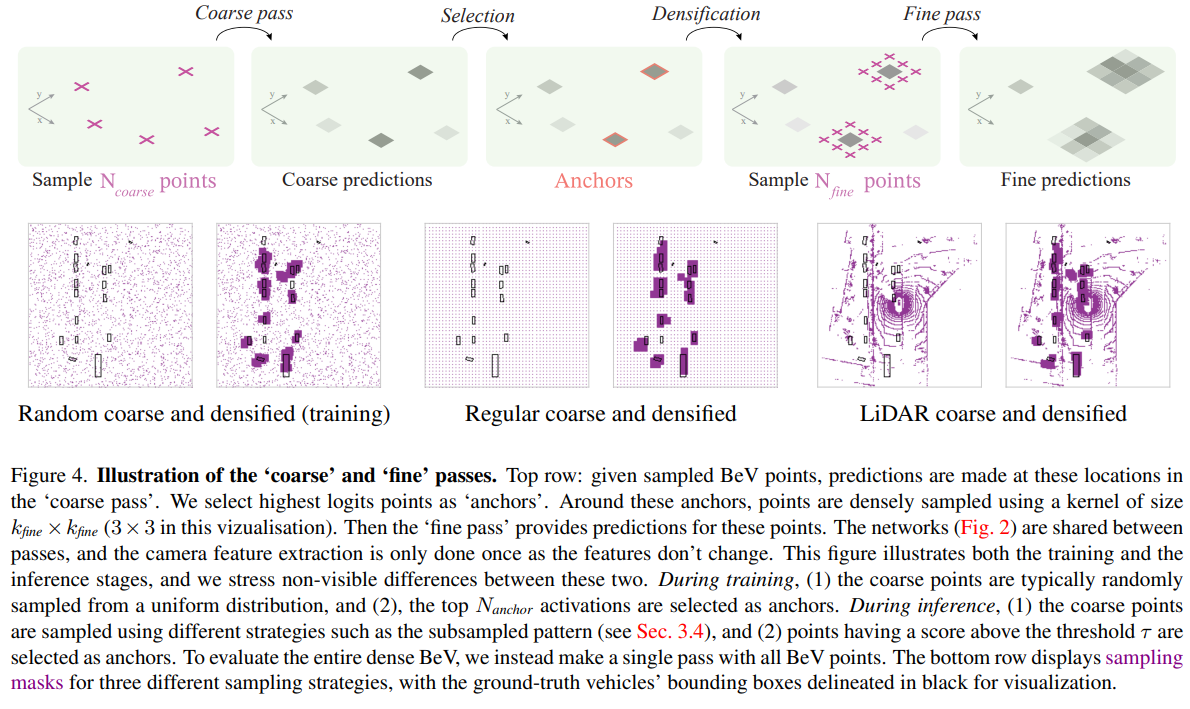
针对seg任务,基于此粗略提取的BEVfeat,继续通过coarse-fine进行调整,具体来说,对上一步的 sparse 2D points作前/背景的2分类预测,然后取topk logist的2D point作为anchor,基于这些前景anchor周围再撒dense 2D points作为上一步sparse 2D point的补充。最终point包括sparse point+dense point。
对上述BEVfeat作时序融合,首先通过warp将不同时间帧feat对齐,然后以 $p^i_t$为中心的window范围内,取2部分点 (key/value) 与 $p^i_t$ (query) 计算attention,其中包括同一时刻window范围内的点 $p^j_t$ 和不同时刻该window范围内的点 $p^m_{t-k}$。