Q:端到端模型通常大致分为几种?
分为两种,一种是完全黑盒OneNet,模型直接优化Planner;另一种是模块化端到端,即模块级联或者并联,通过感知模块,预测模块以及规划模块之间feat-level/query-level的交互,减少分段式自动驾驶模型的误差累积。
Q:[UniAD]
整个框架分为4部分,输入multi-view camera imgs,Backbone模块提取BEV feat,Perception模块完成对于scene-level的感知包括对于agents+ego以及map,Prediction模块基于时序交互以及agents-scene的交互完成对于agents+ego的multi-mode轨迹预测,Planner模块基于预测的轨迹以及BEV feat完成路径的规划。各模块均采用Query+Transformer形式进行构建,方便各模块间信息的交互。
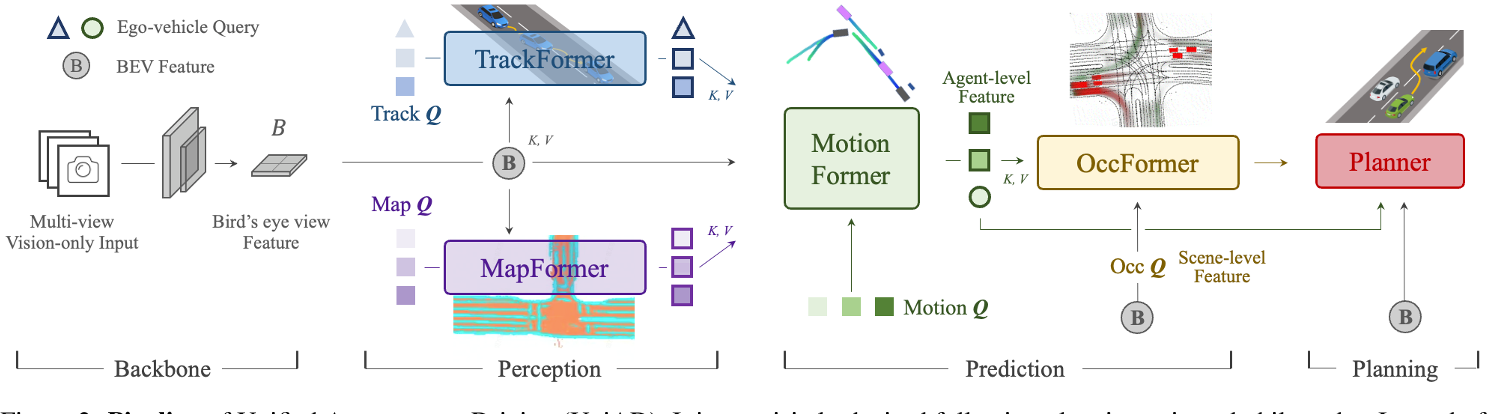
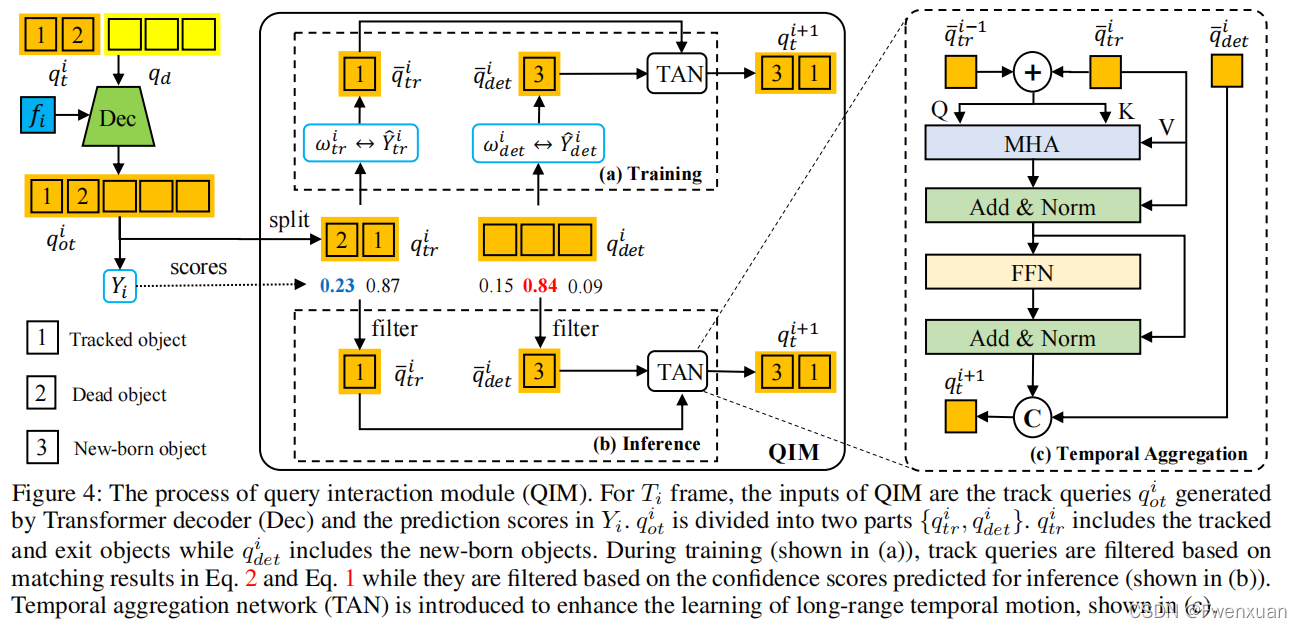
- TrackFormer:query由3部分组成,检测query,跟踪query以及ego query。对于检测部分,对于当前时刻 $t$ ,定义当前时刻的det query $q^t_d$,采用DETR检测模型,用来检测未跟踪到的新目标newborn;对于跟踪部分,每一个query对应其跟踪的对应object,track query $q^t_{tr}$ 的集合长度随着部分object消失而动态变化。 推理过程:following MOTR,训练时对于初始时刻det query采用BEVFormer检测newborn,track query集合为空,后续时刻将当前时刻的det query合并到下一时刻的track query集合中。合并后的query集合即 $cat(q^t_d, q^t_{tr})$ 与BEV feat送入decoder作交互,输出的query经过QIM与上一时刻的track query作MHA获取时序信息,最终输出更新后的 $\hat{q}^t_{tr}$ 。根据预测score用thre来决定newborn加入以及跟踪目标的消失。
- MapFormer:基于Panoptic Segformer(Q2中作详细介绍),对环境进行全景分割,包含两类things和stuff,things表示可记数的实例比如行人或者车辆,每个实例有唯一独立的id区别于其他实例,而stuff表示不可数或者不定形的实例比如天空或者草原,没有实例id。
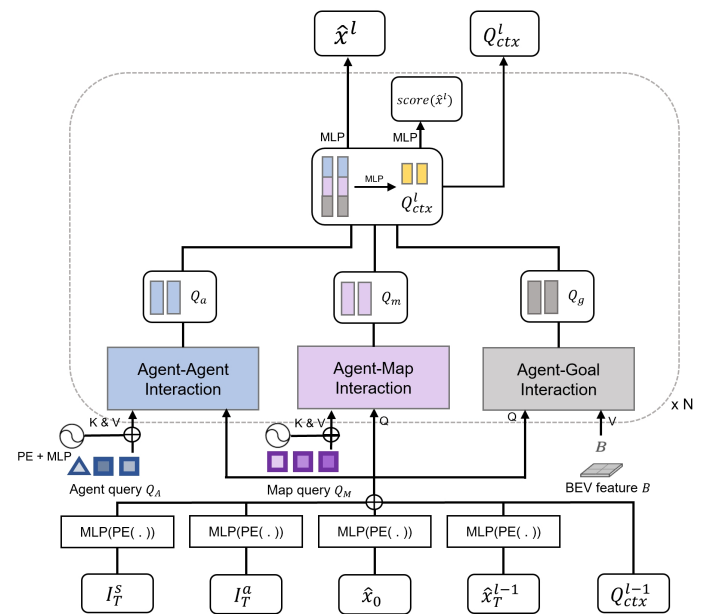
- MotionFormer: agent表示交通参与者包括车辆行人等,goal表示交通参与者的目标位置后者轨迹的终点。 MotionFormer共有3种交互:agent-agent(与表示动态agent的query交互),agent-map(与表示静态map的query交互),agent-goal。agent-agent输入track query和motion query,agent-map输入map query和motion query,agent-goal输入BEV feat和motion query(类似于BEVFormer中通过dcn完成query从BEV feat中extract motion context)。 motion query由5部分组成:当前同一时刻的上一层decoder输出的goal point位置pos信息 $\hat{x}^{l-1}T$ 和query context上下文信息 $Q^{l-1}_{ctx}$,agent当前位置 $\hat{x}_0$,以及位置pos先验信息scene全局坐标系下的anchor end point和agent自车坐标系下clustered anchor end point(先验pos即从gt中利用kmeans对所有agents聚类)。 decoder最终输出每个时刻所有可能轨迹点组成的multi-mode轨迹 $\hat{x}^l$ 即多种可能性的轨迹,training中pre与gt的cost包含3部分,pre轨迹与gt轨迹之间点和点的距离,轨迹运动的物理约束。
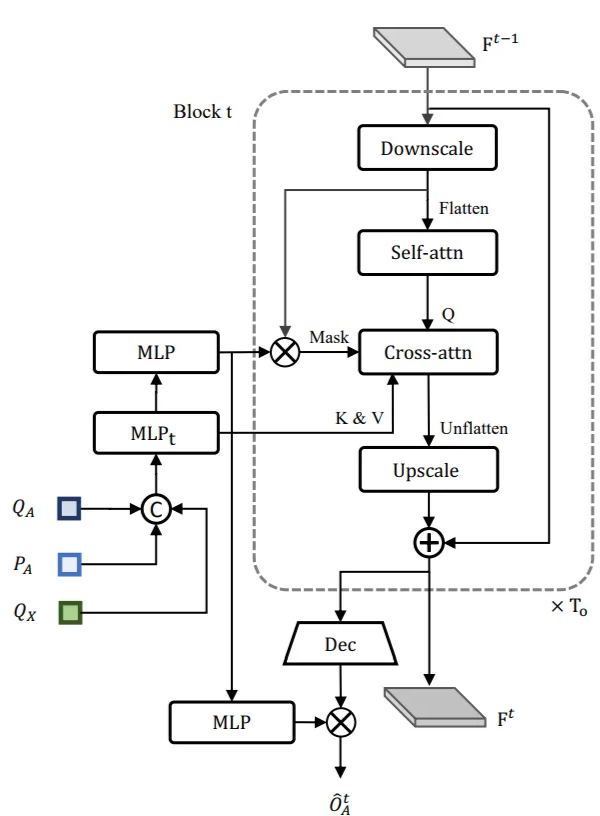
- OccFormer:类似于RNN结构,逻辑也类似于NLP中顺序预测下一时刻词元。由$T_o$个序列block顺序级联,第t个block对应时刻$t$。上一时刻block输出的scene feat $F^{t-1}$以及sparse agent feat作为此时刻的输入,其中sparse agent feat包括TrackFormer输出的track query和agent position,以及MotionFormer输出的motion query(每个agent只取多mode轨迹中score最大值对应的query),表示未来场景中agent-level的知识。 虚线框中pixel-agent interaction采用mask cross-attention使得 dense scene feat 只专注此时刻的agent,专注聚焦局部的相关agent信息。Instance-level occupancy将refined $F^t$ 与coarse mask agent-instance feat 矩阵相乘,得到包含每个agent的id表示的Occ $\hat{O}^t_A$。
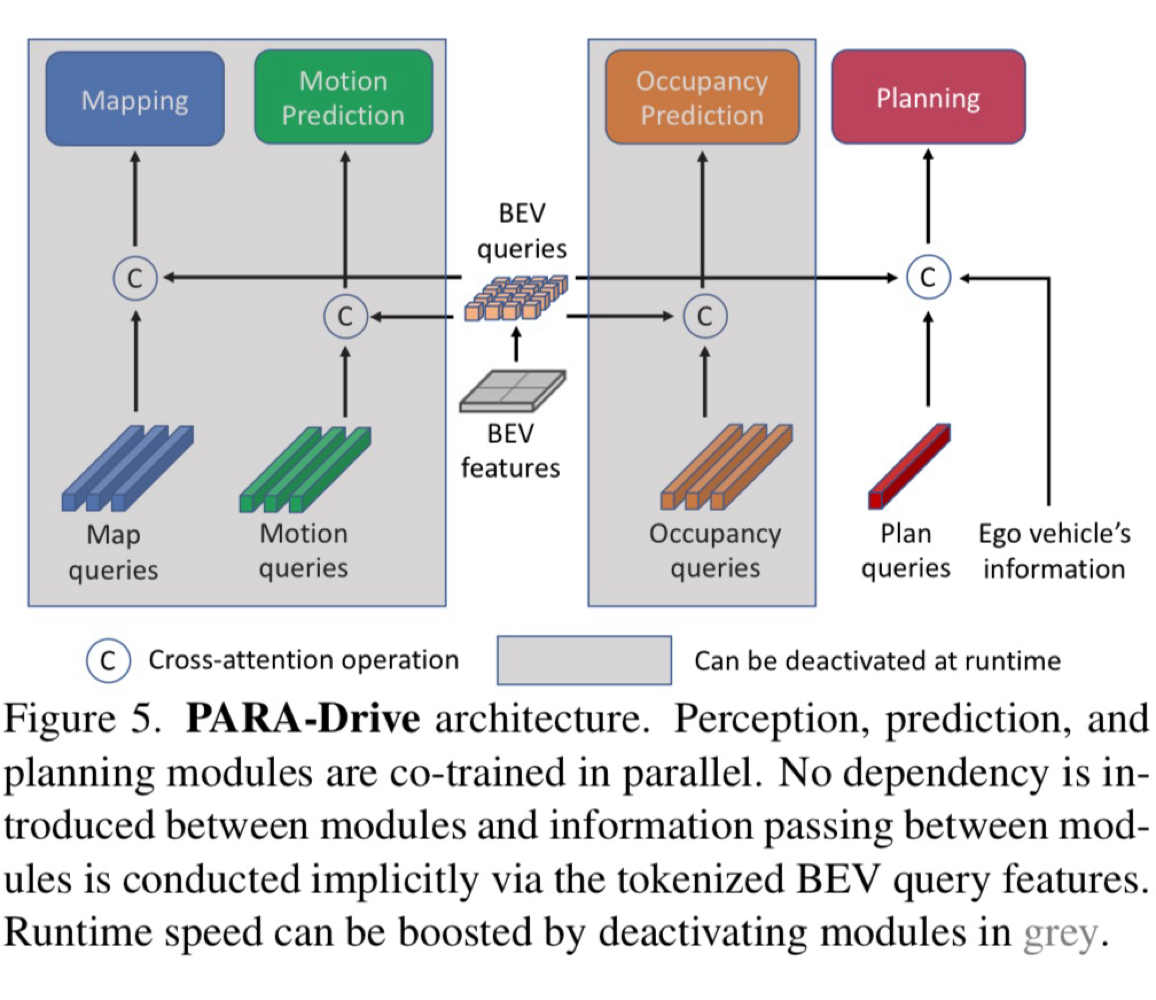
Q:[PARA-Drive]
基于UniAD的各模块,重新调整了感知预测以及规划各模块的连接方式。PARA-Drive中各子模块都采用并行同步协同训练的方式,各模块之间的联系只有updated BEV query(同BEVFormer)。测试推理时可去除Map/Motion/Occ模块,推理速度boost。
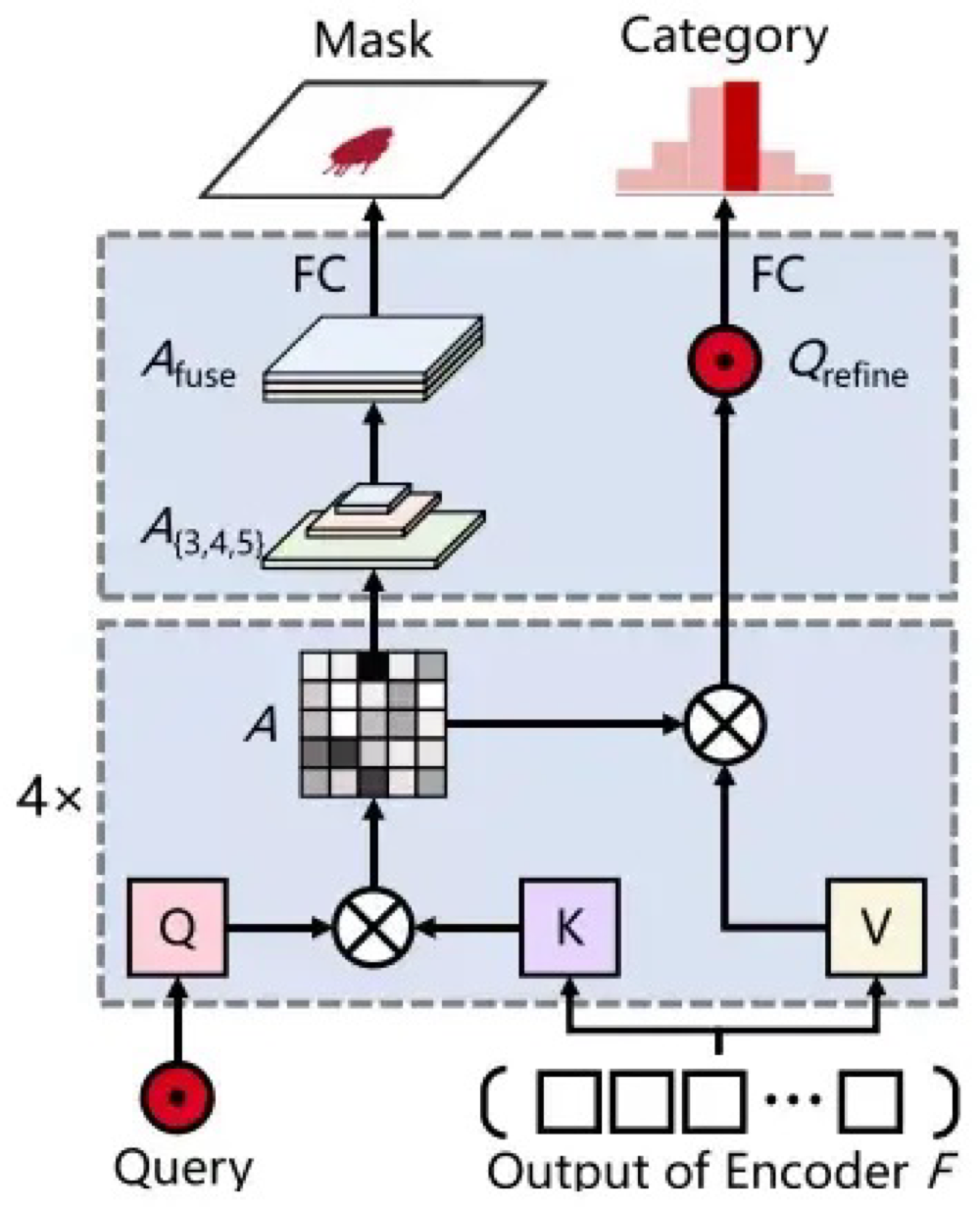
Mapping:Panoptic SegFormer
对于输入RGBbackbone提取2D feat,neck提取多尺度特征 (s8/s16/s32),将多尺度特征flatten后cat得到$C \in \mathbb{R}^{(L_1+L_2+L_3) \times 256}$,作为encoder的输入,进行self-attention得到$F$,decoder分为2步,输入为things和stuff query,第1步用DETR方式refine query,引入目标检测的 location label进行监督训练,推理时去除od的head,第2步将带有od知识的refined query输入mask decoder进一步refine和update,用class和seg label进行监督训练,其中mask decoder采用cross-attention实现,输入query(Q)和feat $F$(K/V),attention map经过split得到不同步长尺度的feat,然后通过上采样统一feat尺寸后cat进行mask的预测,weighted value经过FC预测class。
Q:[SpareDrive]
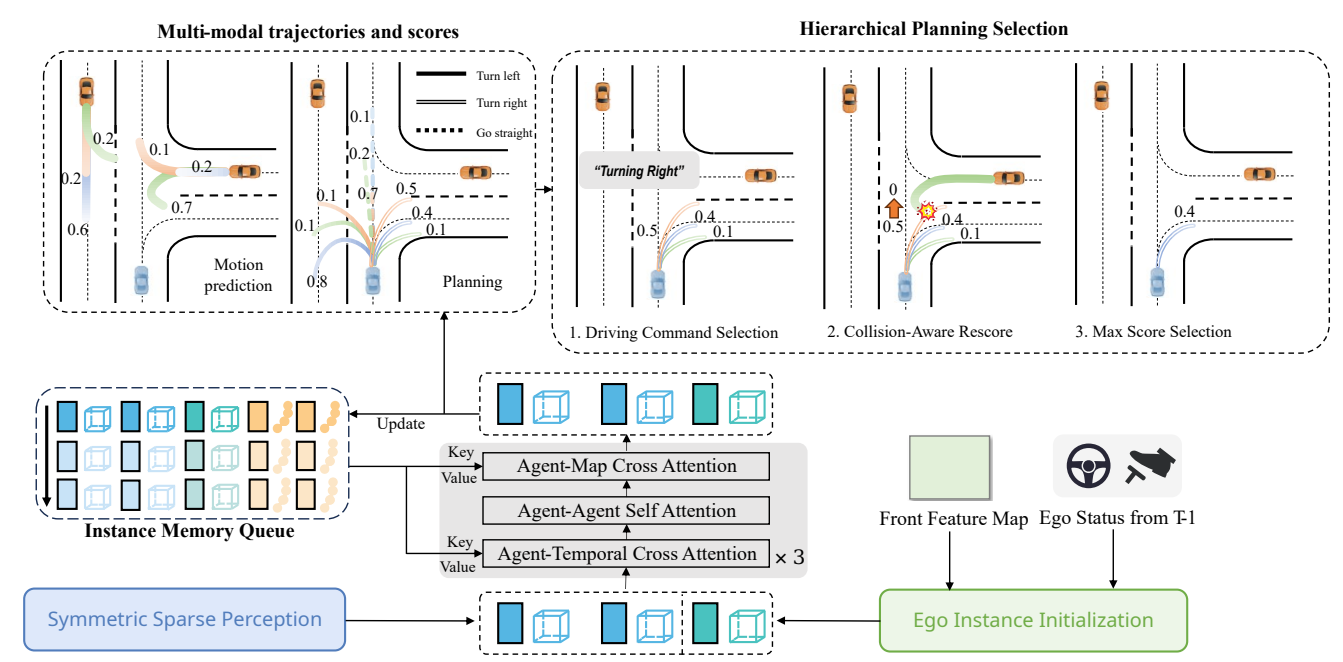
由3部分组成:image encoder提取多尺度多视角2D特征,symmetric sparse perception进行agents和map的感知以及motion planner预测agents和ego的轨迹。
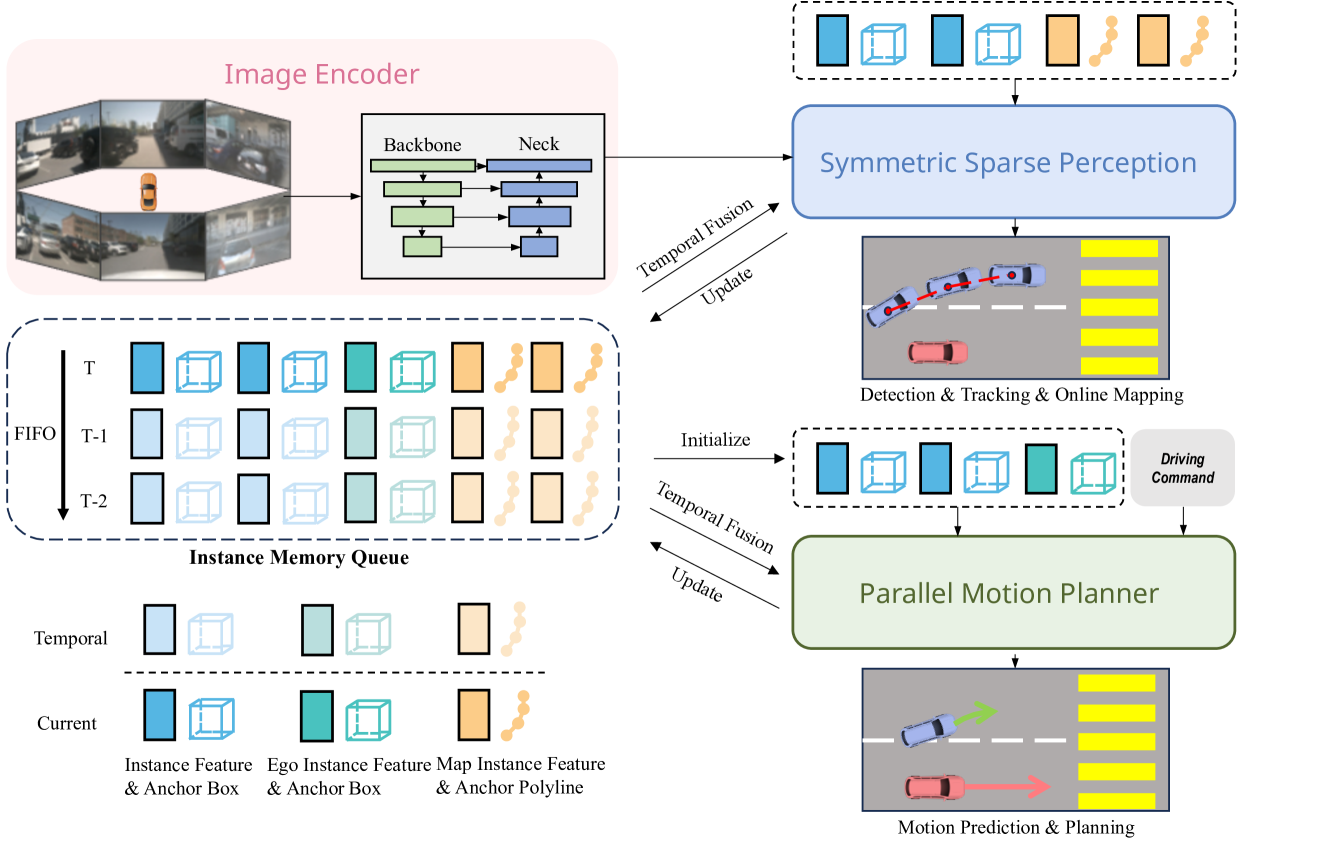
- image encoder:输入为多视角图像,encoder提取 mutli-view multi-scale 2D feat,输出特征 $I={I_s∈ℝ^{N×C×H_s×W_s} \mid 1≤s≤S}$,其中 $N$ 和 $S$分别表示view数量和scale数量;
- symmetric sparse perception:分为左右并行的两部分,分别为agents目标检测和map。
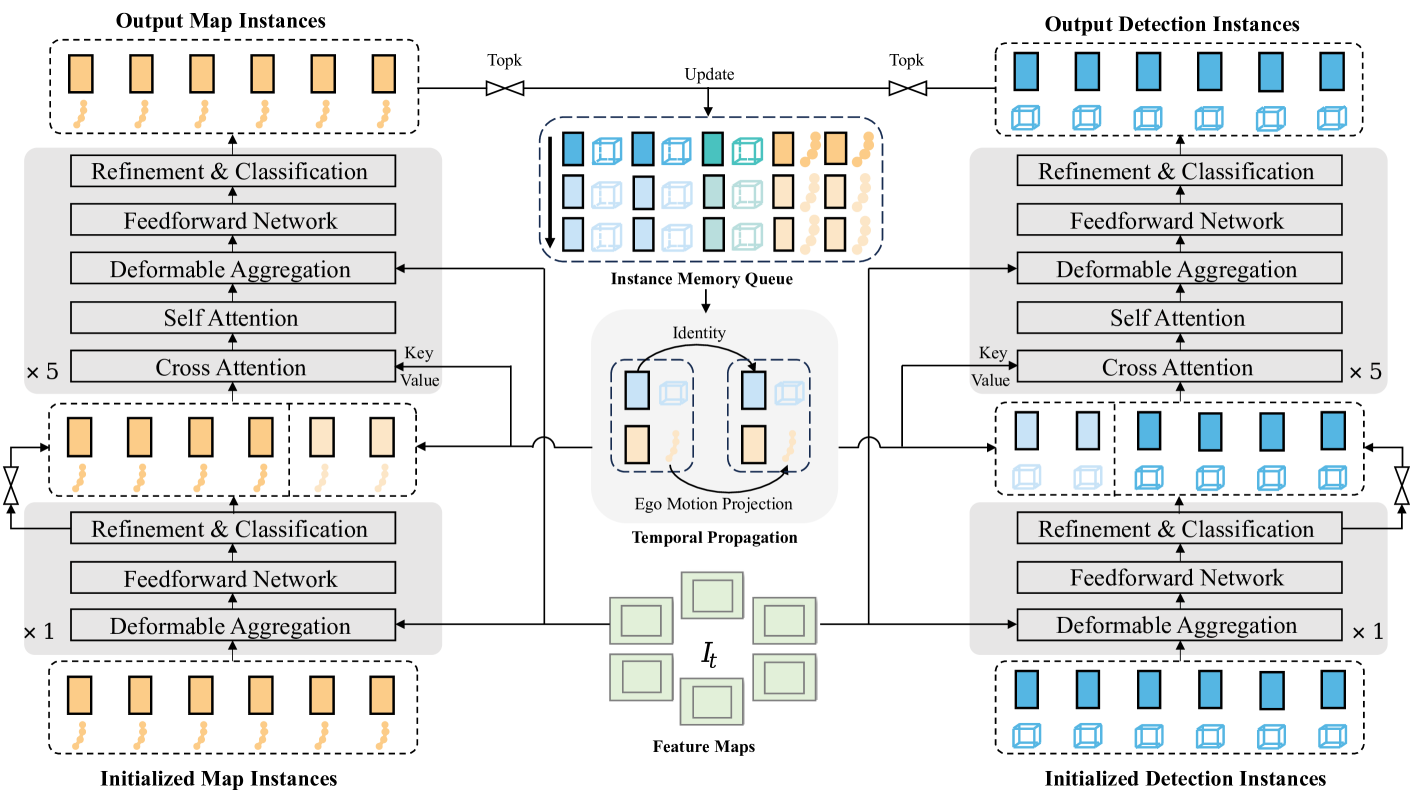
- agents OD任务:采用DETR范式,输入包括特征 $I$ 和query,其中query由 instance feat query $F_d \in \mathbb{R}^{N_d \times C}$和 anchor box query $B_d \in \mathbb{R}^{N_d \times 11}$ 组成,其中 $N_d$ 表示 anchor 数量,box的11维包括位置坐标,长宽高,角度以及速度; 模型结构由$N_{dec}$层decoder构成,其中有$N_{dec}-1$层时序decoder,1层非时序decoder。非时序decoder通过deformable cross-attention update $F_d$,时序decoder对temporal query和当前帧的query作cross-attention,然后当前帧query作self-attention。 时序query即memory queue,用上一帧的refined query取topk来更新,相当于recurrent temporal query,然后warp到当前时刻作cat以及attention。[decoder以及时序融合部分详情见 Sparse4Dv2 ]
- map OM任务:采用DETR范式,结构与OD相同。输入query包括instance feat query $F_m \in \mathbb{R}^{N_m \times C}$和 anchor polyline query $L_m \in \mathbb{R}^{N_p\times N_p \times 2}$ 组成,具体来说共设置 $N_m$ 条anchor polylines,每条polyline包括$N_p$个点,每个点包括$(x_i,y_i)$两个坐标。
- tracking 任务:见Sparse4Dv3中Tracking pipeline,OD训练任务无需添加tracking约束。
- motion planner:由3部分组成:ego instance initialization,
spatial-temporal interactions 和 hierarchical planning selection
- ego instance initialization:query类似于agents,包括 instance feat query $F_e \in \mathbb{R}^{1 \times C}$和 anchor box query $B_e \in \mathbb{R}^{1 \times 11}$ 。对于前者初始化采用smallest feat map of font,既包含了环境的上下文信息又避免了采用上述稀疏感知特征而带来的信息缺失,对于后者初始化速度采用上一帧预测的速度,其余status信息利用辅助任务从$F_e$中解码出
- spatial-temporal interactions:逻辑类似于稀疏感知中的时序融合,但有所不同,之前稀疏感知中的cross-attention是当前帧instance与历史帧所有instance的交互,是scene-level,现在的agent-temporal是instance-level,聚焦的是某个instance与自己的历史instance的交互。query依然包括feat和anchor$F_a = concat(F_d, F_e), B_a = concat(B_d, B_e)$,memory queue共有$H$个历史帧时刻,每个时刻包含$N_d$个agents的feat+anchor以及1个ego的feat+anchor。 最后预测输出周围agents的$T_m \times K_m$条轨迹和$T_p \times K_p$种planning,$T$表示多个timestamp,此外还预测相应的轨迹得分对应$K_m$条轨迹和$K_p$种planning
- hierarchical planning selection:首先,根据驾驶命令cmd选择对应的轨迹集合;接着,结合周围agents的预测的轨迹和自车的planning轨迹,计算碰撞风险,碰撞风险高的轨迹,得分低;最后,选择最高分数的轨迹输出。
Q:[VADv2]
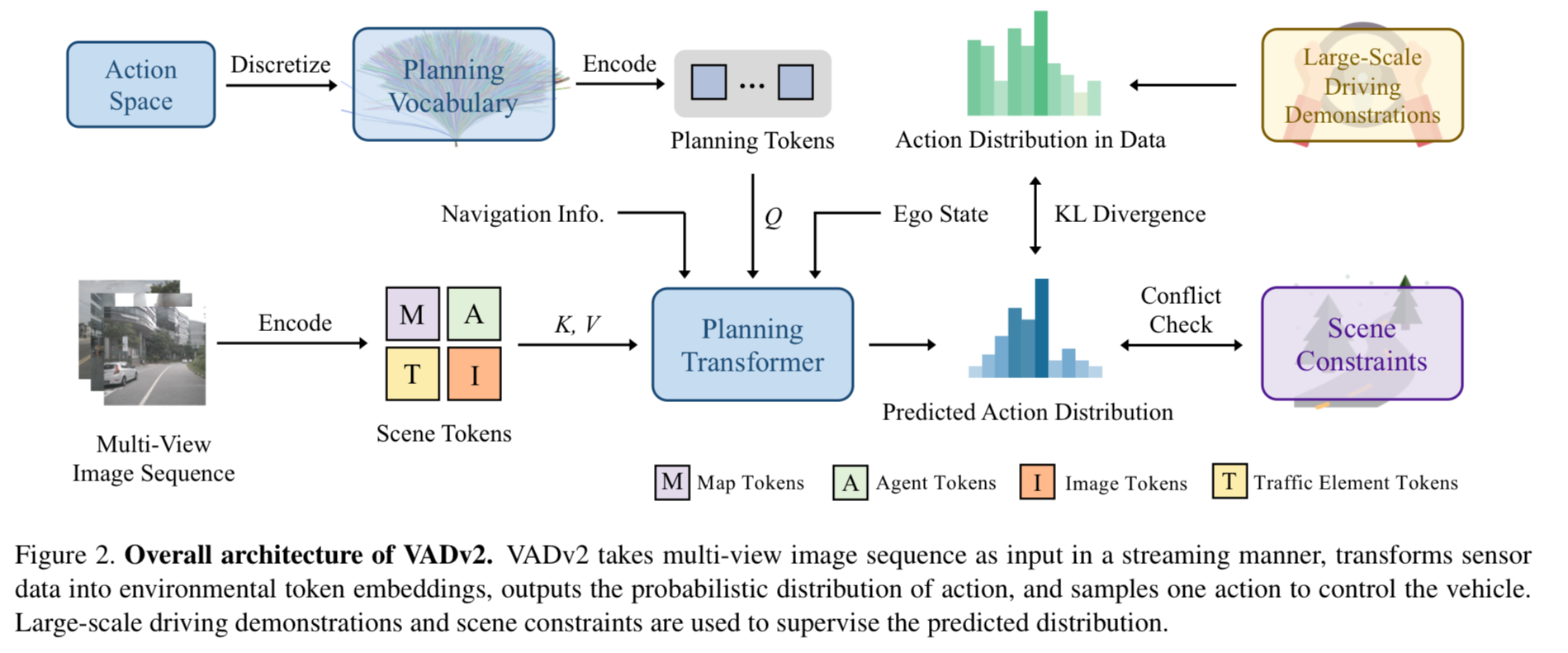
planning transformer输入包括planning token,scene token以及navi token导航/ego status token,通过planning token与scene的交互,最终输出每个action相应的概率,通过概率选出一条action。 通过真实人类轨迹数据集当中action的概率来约束预测action概率,同时保留常见的轨迹冲突代价loss。
- planning token:通过在真实人类驾驶规划action数据集中通过最远距离轨迹采样得到N条具有代表性的action,具体每个轨迹用点表示,然后作MLP得到planning token。
- scene token:输入multi view图片,计算map/agents/traffic element token即提取静态动态不同环境要素pre,同时输入image token补充稀疏pre没有的信息。
- navi/ego token:导航信息和ego status通过MLP也提取相应token。