Q:如何利用时序提升单目depth [AFNet]
single-view对低纹理以及noisy pose更加鲁棒友好,multi-view包含视差,一般采用cost volume对于动态目标效果差,对于noisy pose很敏感。
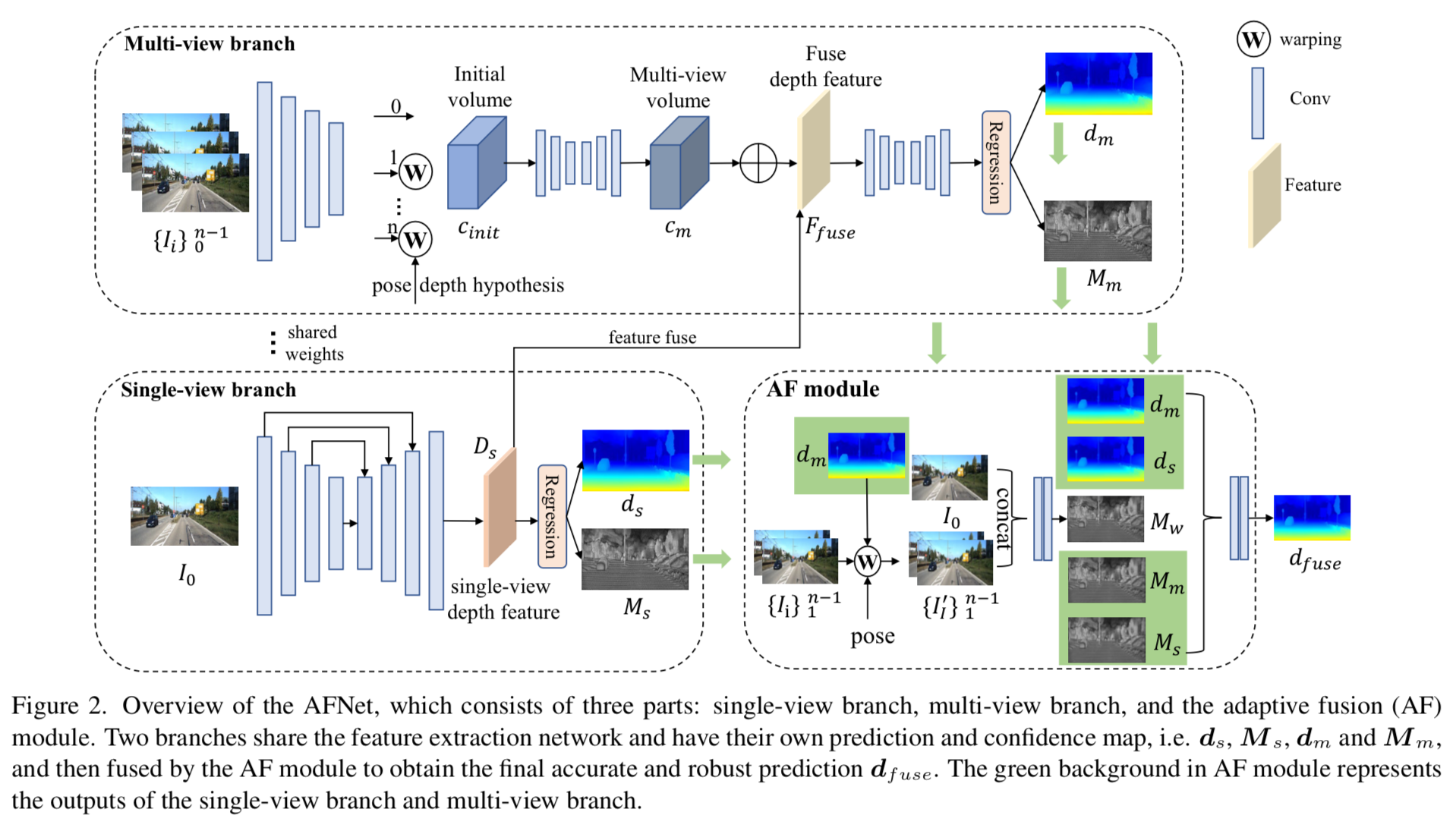
single-view encoder(backbone)输出4 scale feat,特征融合后得到single-view depth feat 即1/4-scale 257-channel的feat,256通道为dpeth probablity volume,通道对应各个离散深度值的可能性概率(离散深度的分类问题),深度值和对应概率加权求和即最终的depth,1通道为confidence map。
multi-view encoder与single-view共享,通过反卷积将4scale的feat统一到1/4 step,利用相机内外参将其他view的feature投影到离散的depth上得到feat volume(warp follow Msvnet),将所有view 的feat volume 通过3D conv和hourglass network 聚合得到 multi-view cost volume。将multi-view cost volume与single-view depth feat相融合以丰富semantic info和detail info,然后cov预测depth和confidence。
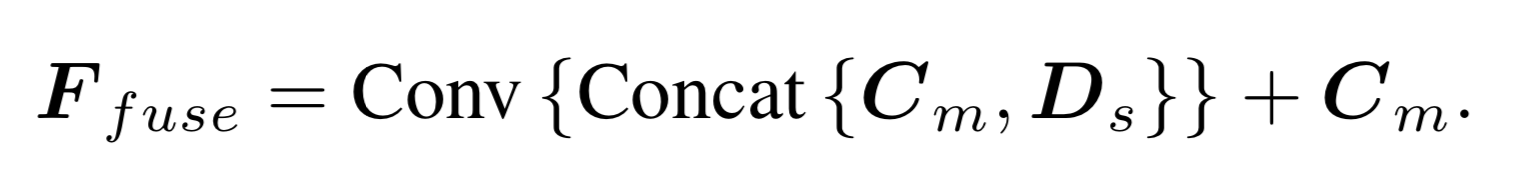
AF模块,首先利用multi-view pre depth和pose将其他view warp到当前view,如果depth不准确那么warp后和当前view对不上,则通过cat和conv得到depth confience判断multi-view网络输出是否准确。最后通过判断两分支预测哪个confidence高,而且准确,则选择作为最后depth。
Q:如何解决不同camera内外参差异带来的depth性能下降 [UniDepth]
解决camera差异带来的depth估计泛化性能下降。
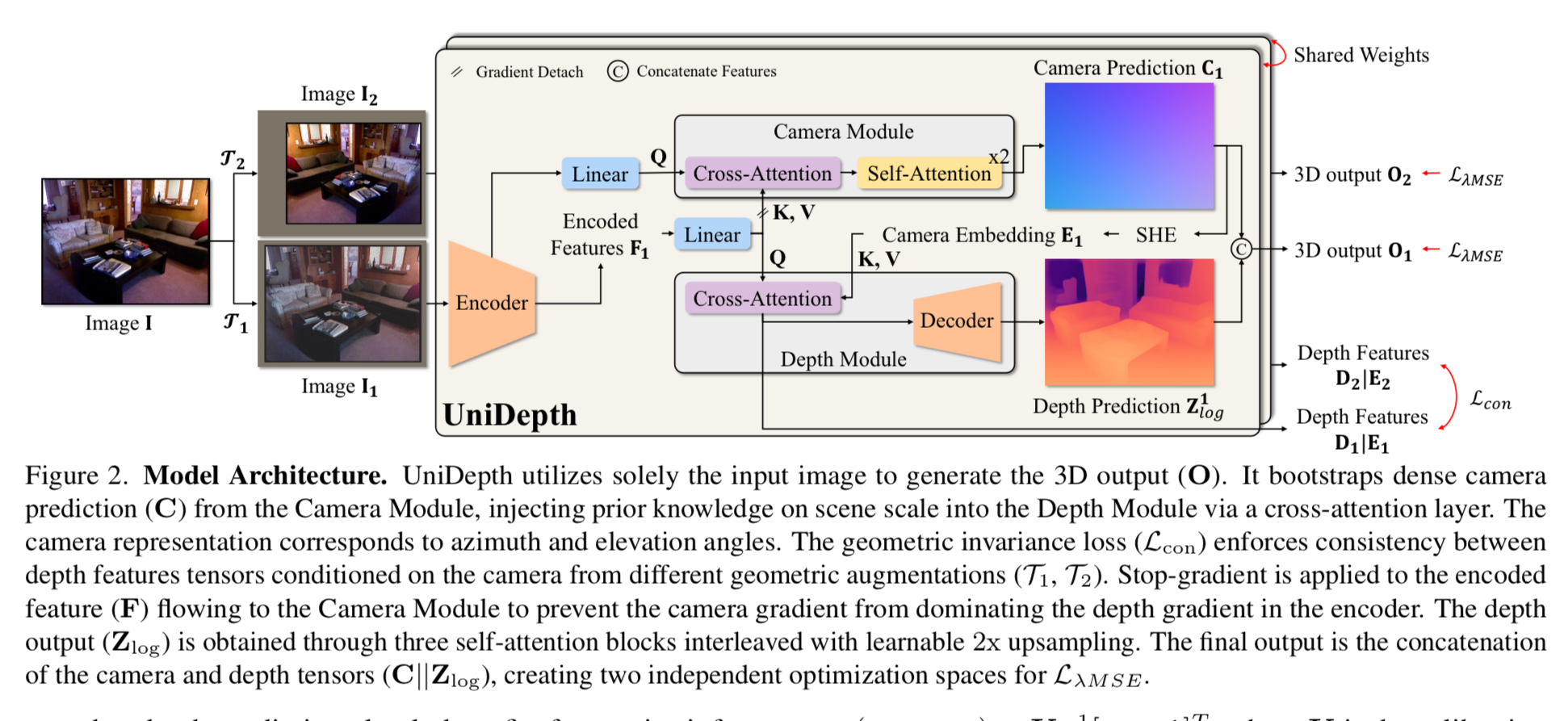
将笛卡尔坐标系解耦为伪球面表示的相机分量(方位角和仰角)以及深度分量,即两个分支camera参数预测和depth预测。
首先通过不同的数据增强模拟不同相机参数的img,对于某个相机参数的img,经过encdoer提取特征feat F,分为两路,一路从中通过MLP提取4个class token,将其作为query通过cross-attention和self-attention从feat F中抽取相机内参残差,用于后续计算相机焦距和光心,基于焦距和光心反投影得到伪球面表示的相机参数,即camera prediction C 的2个通道分别表示方位角和仰角。方位角和仰角通过SHE变换得到camera embedding,从而向depth module中引入尺度先验信息。camera embedding与lineared feat F进行cross-attention,然后经过decoder预测输出depth。
两类约束,3D参数预测输出和GT之间,以及不同相机参数(即不同几何变换数据增强)depth一致性。
Q:深度估计主流方法的分类标准有哪几种,相应的分类有哪几类?
| 分类标准 | 核心维度 | 典型类别 |
|---|---|---|
| 传感器与输入模态 | 硬件配置与数据源 | 1. 单目:成本低,计算效率高,缺乏视差信息,弱纹理区域鲁棒性差,适用于低成本ADAS 2. 双目:精度高,精度依赖姿态估计准确度,受光照影响,适用于障碍物检测和距离测量,对高纹理友好 3. LiDAR/多模态融合:计算复杂度高,适用于高精度估计 |
| 监督信号类型 | 数据标注依赖程度 | 1. 有监督:由Ladar获取的3D点云,L1 loss/L2 loss/SIL loss 2. 自监督:图像重投影误差作为监督,思路类似于双目或者多视角利用位姿及视差,即深度信息结合位姿信息将3D点重投影到2D,L1/L2/平滑性损失 3. 弱监督:— |
| 算法原理 | 技术实现路径 | 几何方法、深度学习方法、混合方法 |
| 时间维度利用 | 是否利用时序信息 | 单帧、多帧 |
| 输出形式 | 深度信息的表示方式 | 密集深度图 稀疏点云 体素网格 |
Q:常见数据集和评价指标有哪些?
一、主要数据集
| 数据集名称 | 类型 | 核心特点 | 适用场景 | 数据量(图像/深度图) |
|---|---|---|---|---|
| NYU Depth V2 | 室内 | - RGB-D 图像(Kinect 采集) - 密集深度标注 - 464 个室内场景 |
单目深度估计模型训练与测试 室内场景分析 |
约 120K 对 |
| ScanNet | 室内 | - 大规模 3D 数据集 - 2.5M 张 RGB-D 图像 - 1500 多个场景 |
多任务学习(语义分割、表面重建) 复杂室内场景建模 |
2.5M 张 |
| DIODE | 室内外 | - 高分辨率 RGB-D 图像 - 激光雷达和结构光传感器获取深度标注 |
复杂光照和几何结构场景 室内外深度估计 |
未明确 |
| KITTI | 室外 | - 自动驾驶经典数据集 - 双目图像 + 激光雷达点云 - 相机标定参数 |
单目/双目深度估计 SLAM 研究 |
约 93K 张 |
| Make3D | 室外 | - RGB 图像 + 激光雷达深度图 - 深度标注较稀疏 |
小规模验证 室外场景深度估计 |
534 对 |
| Cityscapes | 室外 | - 城市街道场景 - 高分辨率图像 - 部分子集包含深度信息 |
城市场景深度估计 语义分割 |
未明确 |
| Virtual KITTI | 合成 | - KITTI 的虚拟版本 - 多视角、多光照条件 - 精确深度标注 |
数据增强 域适应研究 |
未明确 |
| Matterport3D | 合成 | - 90 个建筑场景的 RGB-D 数据 - 适合复杂室内场景建模 |
室内场景建模 多任务学习 |
未明确 |
| Hypersim | 合成 | - 大规模合成数据集 - 精确深度、法线、语义分割标注 - 室内外场景 |
深度估计 多模态学习 |
未明确 |
| WoodScape | 真实 | - 四路鱼眼摄像头(190° FoV) - 多传感器融合生成密集深度图 - 标注语义分割、3D边界框 |
多视角环视深度估计 停车场障碍物检测 鱼眼畸变校正模型验证 |
未明确 |
| ApolloScape Parking | 真实 | - 环视摄像头 + 激光雷达 - 多层停车场、斜列式车位标注 |
复杂停车场环境感知 停车位检测与路径规划 多模态融合研究 |
未明确 |
| KITTI 360 | 真实 | - 扩展版 KITTI - 连续驾驶场景 + 停车场数据 - 双目图像 + 激光雷达点云 |
泊车场景的连续深度估计 动态障碍物跟踪 SLAM 与深度联合优化 |
未明确 |
| PS2.0 | 真实 | - 专注停车位检测 - 鱼眼图像 + 深度信息 - 垂直/平行/斜列式车位标注 |
停车位几何结构感知 车位角点定位精度评估 鱼眼镜头下的深度估计鲁棒性测试 |
未明确 |
| CARLA Parking | 合成 | - CARLA 仿真生成 - 自定义停车场布局与光照 - 精确深度 + 动态障碍物模拟 |
极端场景测试(夜间/雨天) 遮挡恢复能力验证 合成到真实的域适应研究 |
未明确 |
| SynParking | 合成 | - 多摄像头环视系统模拟 - 密集深度图 + 动态行人 - 遮挡场景生成 |
动态障碍物深度一致性评估 实时性测试(FPS) 多视角数据融合算法开发 |
未明确 |
关键对比维度
- 传感器类型:真实数据集中,WoodScape 和 PS2.0 提供鱼眼摄像头数据,适合环视系统开发;ApolloScape 和 KITTI 360 包含 LiDAR,适合多模态融合。
- 场景复杂度:ApolloScape 覆盖多层停车场和斜列式车位,适合复杂几何结构分析;CARLA 和 SynParking 支持自定义极端场景生成。
- 标注类型: WoodScape 和 CARLA 提供密集深度图,适合端到端深度估计;PS2.0 和 ApolloScape 标注停车位角点,适合几何约束优化。
选择建议
- 开发环视泊车系统:首选 WoodScape(真实鱼眼数据) + CARLA Parking(极端场景模拟)。
- 停车位检测研究:PS2.0(几何标注) + ApolloScape(复杂停车场)。
- 实时性要求高:SynParking(轻量合成数据) + KITTI 360(真实动态场景)。
- 室内场景:优先使用 NYU Depth V2 或 ScanNet,评价指标推荐 AbsRel 和 RMSE。
- 自动驾驶:KITTI 为主,关注 RMSE 和 δ1.25。
- 合成到真实迁移:Virtual KITTI + 真实数据集,结合 SILog 分析域适应效果。
二、常用评价指标
1. 绝对误差指标
- RMSE (Root Mean Squared Error)
$ \text{RMSE} = \sqrt{\frac{1}{N} \sum_{i=1}^N (d_i - \hat{d}_i)^2} $
- 特点:对深度误差敏感,大误差惩罚更重,广泛用于 KITTI 等数据集。
- MAE (Mean Absolute Error)
$ \text{MAE} = \frac{1}{N} \sum_{i=1}^N |d_i - \hat{d}_i| $
- 特点:反映平均绝对偏差,鲁棒性优于 RMSE。
2. 相对误差指标
- AbsRel (Absolute Relative Error)
$ \text{AbsRel} = \frac{1}{N} \sum_{i=1}^N \frac{|d_i - \hat{d}_i|}{d_i} $
- 特点:归一化误差,适合不同尺度场景的比较。
- SqRel (Squared Relative Error) $ \text{SqRel} = \frac{1}{N} \sum_{i=1}^N \frac{(d_i - \hat{d}_i)^2}{d_i} $
3. 阈值准确率
- δ < threshold
- 定义:预测值与真实值比值在阈值范围内的像素占比。
- 常用阈值:δ1.25 ($\max(\frac{\hat{d}}{d}, \frac{d}{\hat{d}}) < 1.25$)、δ1.25²、δ1.25³。
- 特点:衡量预测结果的可靠性,δ1.25 越高越好。
4. 其他指标
- SILog (Scale-Invariant Logarithmic Error)
- 公式:结合对数域误差和尺度不变性,减少深度尺度漂移的影响。
- iRMSE (Inverse RMSE)
- 公式:计算逆深度(1/d)的 RMSE,适用于远距离深度估计。